原文来自微信公众号
协同过滤
-
定义
协同过滤 就是协同大家的反馈、评价和意见一起对海量的信息进行过滤,从中筛选出目标用户可能感兴趣的信息的推荐过程。
-
商品推荐的例子:
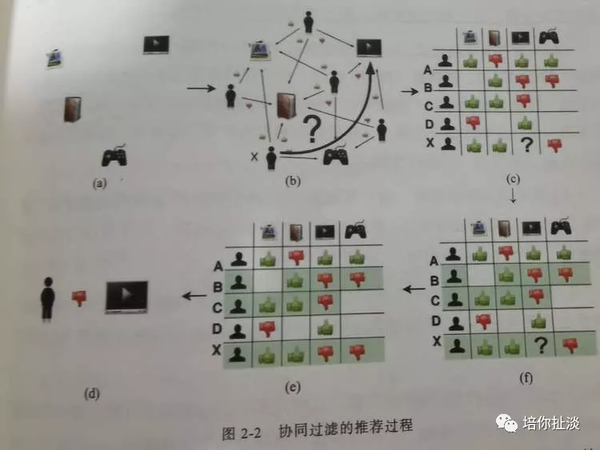
-
电商网站的商品库里一共有四件商品
-
用户X访问该电商网站,电商网站的推荐系统需要决定是否推荐电视机给用户X
-
将用户商品图转化成矩阵的形式,被称作“共现矩阵”,好评记为1,差评记为0,没有的可以取评分的均值
-
推荐问题转换成预测矩阵中问号元素的值的问题。
-
从共现矩阵中得知,用户B和用户C跟用户X的行向量近似,被选为Top n(n取2)的相似用户
-
相似用户对“电视机”的评价是负面的,因此预测用户X对“电视机”的评价也是负面的
-
UserCF
基于用户相似度进行推荐,被称为基于用户的协同过滤,如上所示
优点
符合人们直觉上的“兴趣相似的朋友喜欢的物品,我也喜欢”的思想
缺点
互联网应用场景下,用户数远远大于物品数,因此UserCF的用户相似矩阵存储开销非常大
用户的历史数据向量非常稀疏,对于只有几次购买或者点击行为用户而言,找到相似的用户准确率非常低
-
ItemCF
基于物品相似度进行推荐的协同过滤算法。
具体步骤:
-
构建用户-物品m*n维的共现矩阵
-
计算任意列向量间的相似性,构建n*n维物品相似度矩阵
-
获取用户历史行为数据中正反馈物品列表
-
利用物品相似度矩阵,找出与用户正反馈物品相似的Top k个物品,组成相似物品集合
-
对相似物品集合,根据相似度分值排序生成最终排序列表
应用场景
-
UserCF具备更强的社交性,可以通过“朋友”的动态快速更新自己的推荐列表,适用于新闻推荐场景
-
ItemCF适用于兴趣变化较为稳定的应用,如电商场景
特点
-
直观、解释性强
-
头部效应较明显、泛化能力弱
-
无法有效地引入用户特征、物品特征和上下文特征
相似度计算
-
余弦相似度
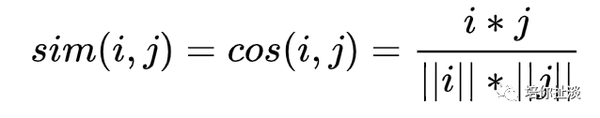
缺点:对绝对值大小不敏感,在某些情况下会出问题。如:用户A对两部电影评分分别是1分和2分,用户B对两部电影评分分别是4分和5分,通过余弦相似度计算,两个用户相似度为0.98。
-
皮尔逊相关系数
通过使用用户平均分对各独立评分进行修正,减小了用户评分偏置影响
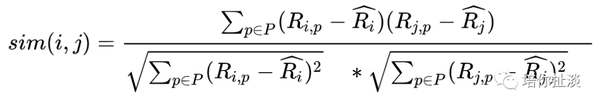
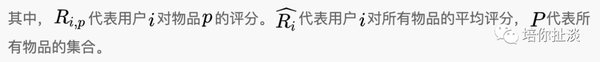
-
改进的皮尔逊相关系数
引入物品平均分的方式,减少物品评分偏置对结果的影响
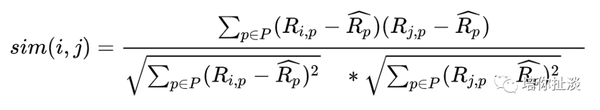
矩阵分解算法
-
原理
将用户和物品映射到同一个表示空间上,得到用户隐向量和物品隐向量,通过用户隐向量与物品隐向量的相似度给用户推荐。
矩阵分解算法将协同过滤生成的m*n维共现矩阵R分解成m*k维用户矩阵U和k*n维物品矩阵V,其中m是用户数,n是物品数,k是隐向量维数。
用户u对物品i的预估评分如下,其中pu是用户矩阵U中对应行向量,qi是物品矩阵V中的列向量
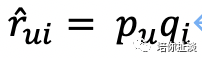
-
求解过程
特征分解
只能作用于方阵,因此不能用于推荐。
特征分解是将方阵A分解成如下形式,其中Q是方阵A特征向量组成的矩阵,