1. 赛题背景
校园一卡通是集身份认证、金融消费、数据共享等多项功能于一体的信息集成系统。在为师生提供优质、高效信息化服务的同时,系统自身也积累了大量的历史记录,其中蕴含着学生的消费行为以及学校食堂等各部门的运行状况等信息。
很多高校基于校园一卡通系统进行“智慧校园”的相关建设,例如《扬子晚报》2016年 1月 27日的报道:《南理工给贫困生“暖心饭卡补助”》。
不用申请,不用审核,饭卡上竟然能悄悄多出几百元……记者昨天从南京理工大学独家了解到,南理工教育基金会正式启动了“暖心饭卡”
项目,针对特困生的温饱问题进行“精准援助”。
项目专门针对贫困本科生的“温饱问题”进行援助。在学校一卡通中心,教育基金会的工作人员找来了全校一万六千余名在校本科生 9 月中旬到
11月中旬的刷卡记录,对所有的记录进行了大数据分析。最终圈定了 500余名“准援助对象”。
南理工教育基金会将拿出“种子基金”100万元作为启动资金,根据每位贫困学生的不同情况确定具体的补助金额,然后将这些钱“悄无声息”的打入学生的饭卡中,保证困难学生能够吃饱饭。
——《扬子晚报》2016年 1月 27日:南理工给贫困生“暖心饭卡补助”本赛题提供国内某高校校园一卡通系统一个月的运行数据,希望参赛者使用
数据分析和建模的方法,挖掘数据中所蕴含的信息,分析学生在校园内的学习生活行为,为改进学校服务并为相关部门的决策提供信息支持。
2. 分析目标
-
1. 分析学生的消费行为和食堂的运营状况,为食堂运营提供建议。
-
2. 构建学生消费细分模型,为学校判定学生的经济状况提供参考意见。
3. 数据说明
附件是某学校 2019年 4月 1 日至 4月 30日的一卡通数据
一共3个文件:data1.csv、data2.csv、data3.csv
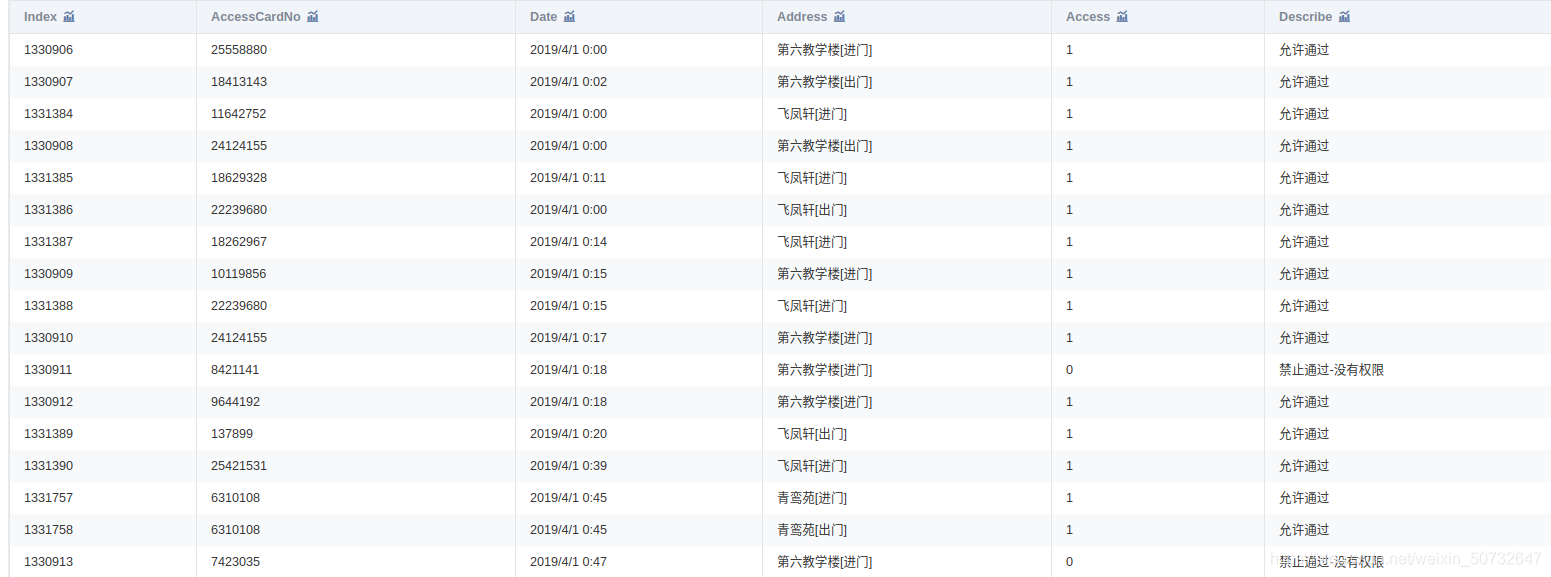
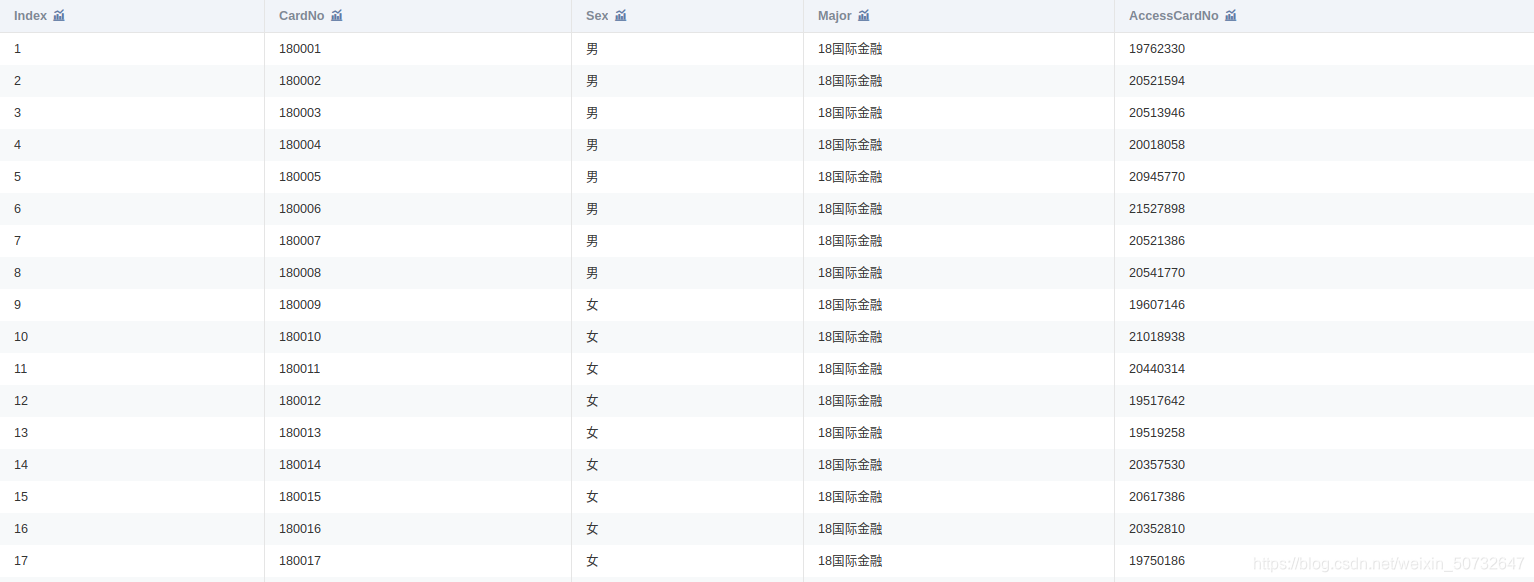
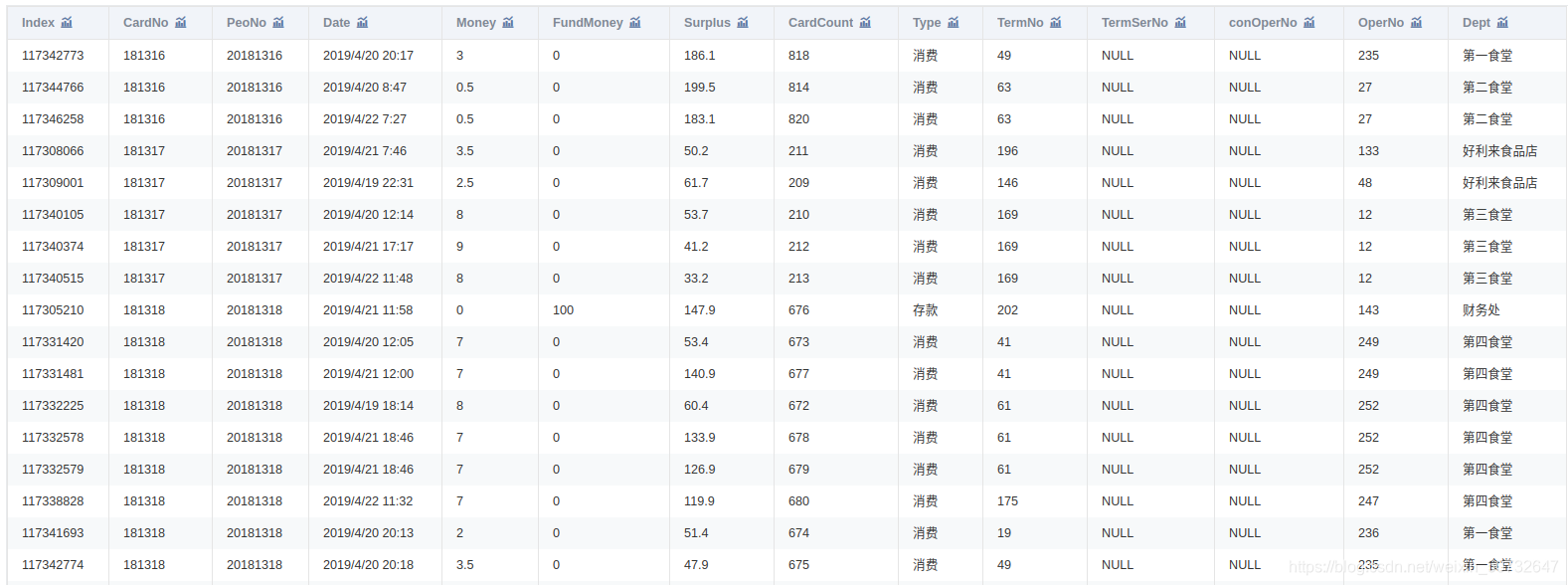
4. 数据预处理
将附件中的
data1.csv、data2.csv、data3.csv三份文件加载到分析环境,对照附录一,理解字段含义。探查数据质量并进行缺失值和异常值等方面的必要处理。将处理结果保存为“task1_1_X.csv”(如果包含多张数据表,X可从
1 开始往后编号),并在报告中描述处理过程。
import numpy as np
import pandas as pd
import os
os.chdir(\'/home/kesci/input/2019B1631\')
data1 = pd.read_csv("data1.csv", encoding="gbk")
data2 = pd.read_csv("data2.csv", encoding="gbk")
data3 = pd.read_csv("data3.csv", encoding="gbk")
data1.head(3)
data1.columns = [\'序号\', \'校园卡号\', \'性别\', \'专业名称\', \'门禁卡号\']
data1.dtypes
data1.to_csv(\'/home/kesci/work/output/2019B/task1_1_1.csv\', index=False, encoding=\'gbk\')
data2.head(3)
将 data1.csv中的学生个人信息与 data2.csv中的消费记录建立关联,处理结果保存为“task1_2_1.csv”;将 data1.csv
中的学生个人信息与data3.csv 中的门禁进出记录建立关联,处理结果保存为“task1_2_2.csv”。
data1 = pd.read_csv("/home/kesci/work/output/2019B/task1_1_1.csv", encoding="gbk")
data2 = pd.read_csv("/home/kesci/work/output/2019B/task1_1_2.csv", encoding="gbk")
data3 = pd.read_csv("/home/kesci/work/output/2019B/task1_1_3.csv", encoding="gbk")
data1.head(3)
5. 数据分析
5.1 食堂就餐行为分析
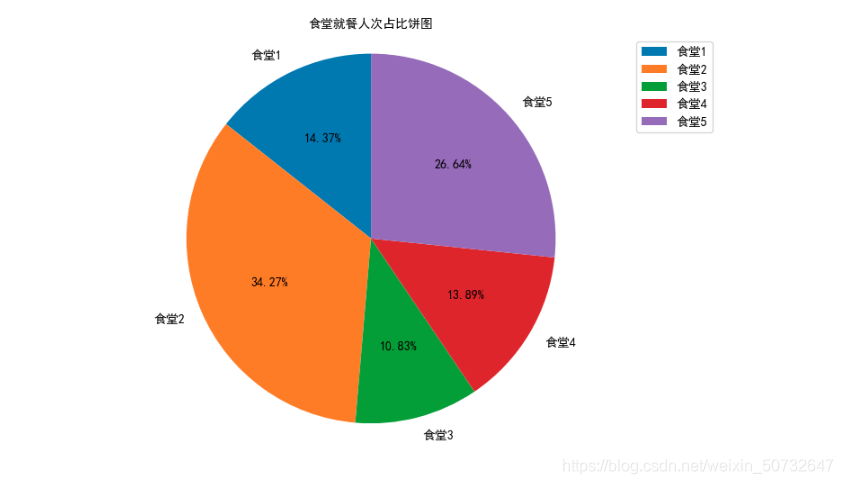
绘制各食堂就餐人次的占比饼图,分析学生早中晚餐的就餐地点是否有显著差别,并在报告中进行描述。(提示:时间间隔非常接近的多次刷卡记录可能为一次就餐行为)
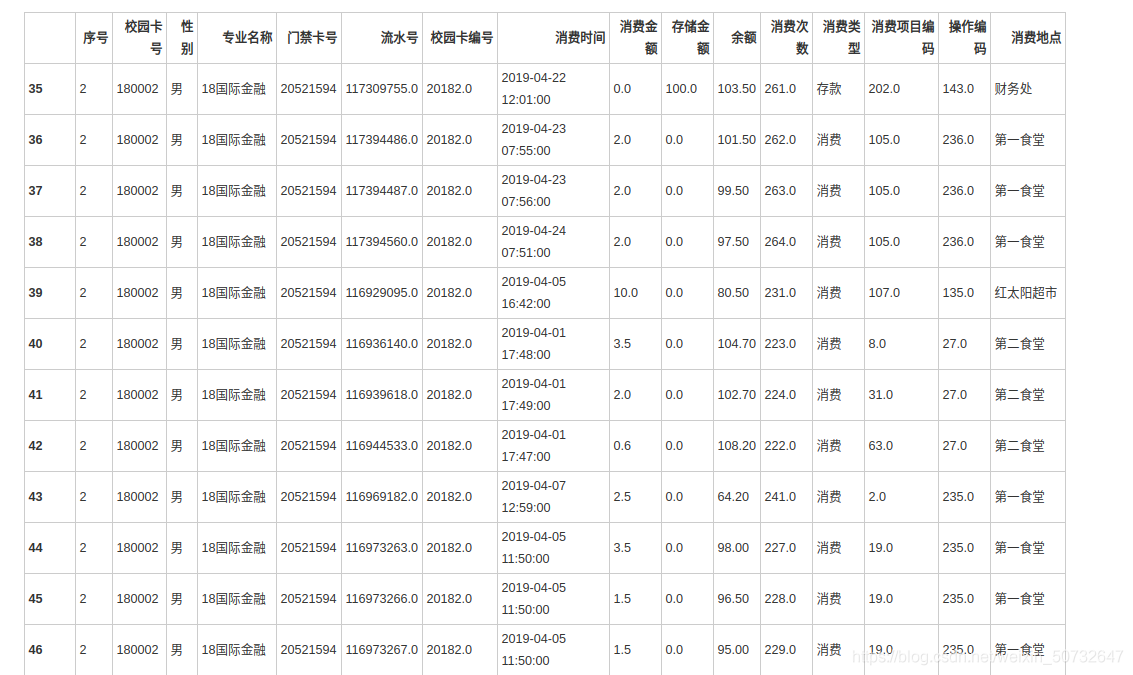
data = pd.read_csv(\'/home/kesci/work/output/2019B/task1_2_1.csv\', encoding=\'gbk\')
data.head()
import matplotlib as mpl
import matplotlib.pyplot as plt
# notebook嵌入图片
%matplotlib inline
# 提高分辨率
%config InlineBackend.figure_format=\'retina\'
from matplotlib.font_manager import FontProperties
font = FontProperties(fname="/home/kesci/work/SimHei.ttf")
import warnings
warnings.filterwarnings(\'ignore\')
canteen1 = data[\'消费地点\'].apply(str).str.contains(\'第一食堂\').sum()
canteen2 = data[\'消费地点\'].apply(str).str.contains(\'第二食堂\').sum()
canteen3 = data[\'消费地点\'].apply(str).str.contains(\'第三食堂\').sum()
canteen4 = data[\'消费地点\'].apply(str).str.contains(\'第四食堂\').sum()
canteen5 = data[\'消费地点\'].apply(str).str.contains(\'第五食堂\').sum()
# 绘制饼图
canteen_name = [\'食堂1\', \'食堂2\', \'食堂3\', \'食堂4\', \'食堂5\']
man_count = [canteen1,canteen2,canteen3,canteen4,canteen5]
# 创建画布
plt.figure(figsize=(10, 6), dpi=50)
# 绘制饼图
plt.pie(man_count, labels=canteen_name, autopct=\'%1.2f%%\', shadow=False, startangle=90, textprops={\'fontproperties\':font})
# 显示图例
plt.legend(prop=font)
# 添加标题
plt.title("食堂就餐人次占比饼图", fontproperties=font)
# 饼图保持圆形
plt.axis(\'equal\')
# 显示图像
plt.show()
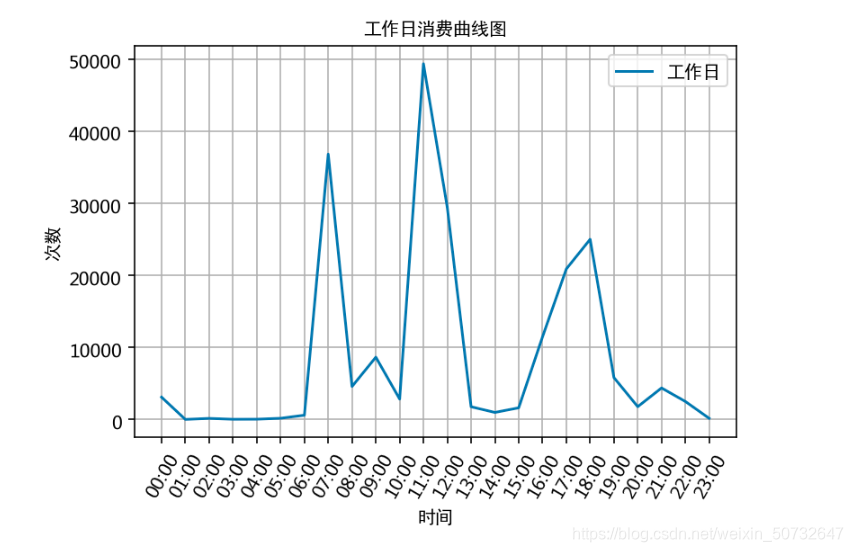
通过食堂刷卡记录,分别绘制工作日和非工作日食堂就餐时间曲线图,分析食堂早中晚餐的就餐峰值,并在报告中进行描述。
# 对data中消费时间数据进行时间格式转换,转换后可作运算,coerce将无效解析设置为NaT
data.loc[:,\'消费时间\'] = pd.to_datetime(data.loc[:,\'消费时间\'],format=\'%Y-%m-%d %H:%M\',errors=\'coerce\')
data.dtypes
# 创建一个消费星期列,根据消费时间计算出消费时间是星期几,Monday=1, Sunday=7
data[\'消费星期\'] = data[\'消费时间\'].dt.dayofweek + 1
data.head(3)
# 以周一至周五作为工作日,周六日作为非工作日,拆分为两组数据
work_day_query = data.loc[:,\'消费星期\'] <= 5
unwork_day_query = data.loc[:,\'消费星期\'] > 5
work_day_data = data.loc[work_day_query,:]
unwork_day_data = data.loc[unwork_day_query,:]
# 计算工作日消费时间对应的各时间的消费次数
work_day_times = []
for i in range(24):
work_day_times.append(work_day_data[\'消费时间\'].apply(str).str.contains(\' {:02d}:\'.format(i)).sum())
# 以时间段作为x轴,同一时间段出现的次数和作为y轴,作曲线图
x = []
for i in range(24):
x.append(\'{:02d}:00\'.format(i))
# 绘图
plt.plot(x, work_day_times, label=\'工作日\')
# x,y轴标签
plt.xlabel(\'时间\', fontproperties=font);
plt.ylabel(\'次数\', fontproperties=font)
# 标题
plt.title(\'工作日消费曲线图\', fontproperties=font)
# x轴倾斜60度
plt.xticks(rotation=60)
# 显示label
plt.legend(prop=font)
# 加网格
plt.grid()
# 计算飞工作日消费时间对应的各时间的消费次数
unwork_day_times = []
for i in range(24):
unwork_day_times.append(unwork_day_data[\'消费时间\'].apply(str).str.contains(\' {:02d}:\'.format(i)).sum())
# 以时间段作为x轴,同一时间段出现的次数和作为y轴,作曲线图
x = []
for i in range(24):
x.append(\'{:02d}:00\'.format(i))
plt.plot(x, unwork_day_times, label=\'非工作日\')
plt.xlabel(\'时间\', fontproperties=font);
plt.ylabel(\'次数\', fontproperties=font)
plt.title(\'非工作日消费曲线图\', fontproperties=font)
plt.xticks(rotation=60)
plt.legend(prop=font)
plt.grid()
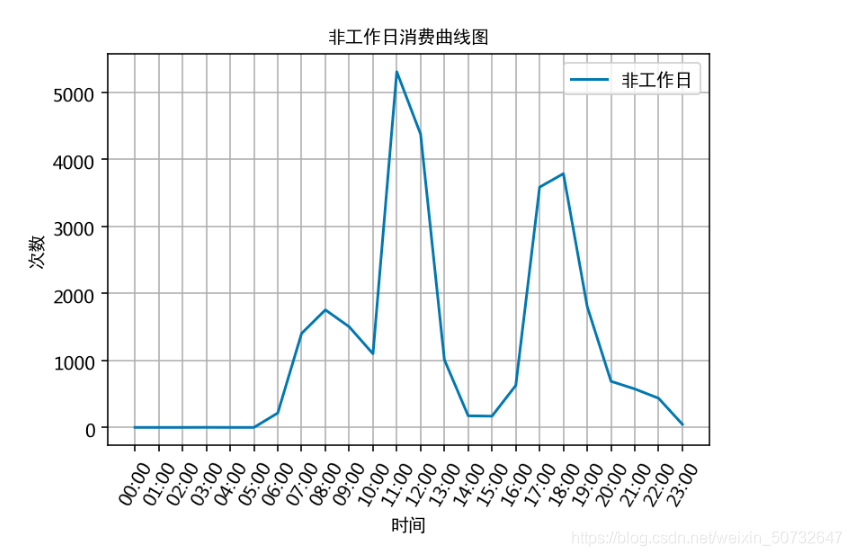
根据上述分析的结果,很容易为食堂的运营提供建议,比如错开高峰等等。
5.2 学生消费行为分析
根据学生的整体校园消费数据,计算本月人均刷卡频次和人均消费额,并选择 3个专业,分析不同专业间不同性别学生群体的消费特点。
data = pd.read_csv(\'/home/kesci/work/output/2019B/task1_2_1.csv\', encoding=\'gbk\')
data.head()

# 计算人均刷卡频次(总刷卡次数/学生总人数)
cost_count = data[\'消费时间\'].count()
student_count = data[\'校园卡号\'].value_counts(dropna=False).count()
average_cost_count = int(round(cost_count / student_count))
average_cost_count
# 计算人均消费额(总消费金额/学生总人数)
cost_sum = data[\'消费金额\'].sum()
average_cost_money = int(round(cost_sum / student_count))
average_cost_money
# 选择消费次数最多的3个专业进行分析
data[\'专业名称\'].value_counts(dropna=False)
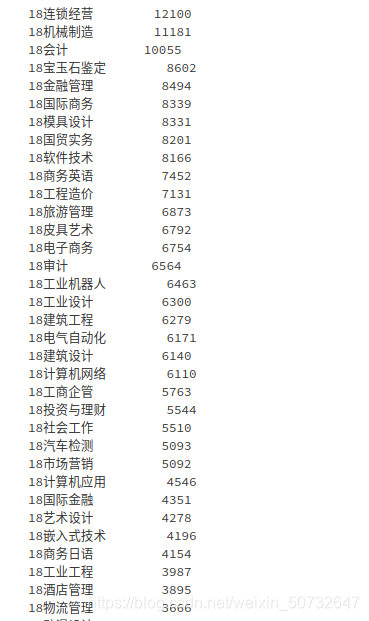
# 消费次数最多的3个专业为 连锁经营、机械制造、会计
major1 = data[\'专业名称\'].apply(str).str.contains(\'18连锁经营\')
major2 = data[\'专业名称\'].apply(str).str.contains(\'18机械制造\')
major3 = data[\'专业名称\'].apply(str).str.contains(\'18会计\')
major4 = data[\'专业名称\'].apply(str).str.contains(\'18机械制造(学徒)\')
data_new = data[(major1 | major2 | major3) ^ major4]
data_new[\'专业名称\'].value_counts(dropna=False)
分析 每个专业,不同性别 的学生消费特点
data_male = data_new[data_new[\'性别\'] == \'男\']
data_female = data_new[data_new[\'性别\'] == \'女\']
data_female.head()
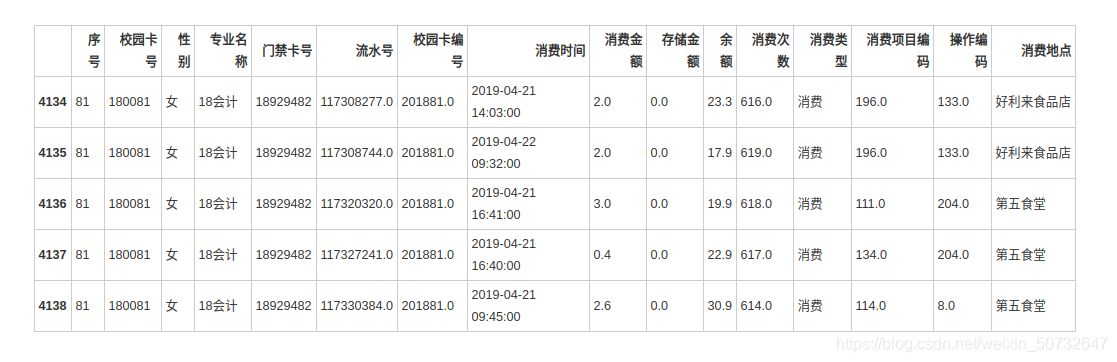
根据学生的整体校园消费行为,选择合适的特征,构建聚类模型,分析每一类学生群体的消费特点。
data[\'专业名称\'].value_counts(dropna=False).count()
# 选择特征:性别、总消费金额、总消费次数
data_1 = data[[\'校园卡号\',\'性别\']].drop_duplicates().reset_index(drop=True)
data_1[\'性别\'] = data_1[\'性别\'].astype(str).replace(({\'男\': 1, \'女\': 0}))
data_1.set_index([\'校园卡号\'], inplace=True)
data_2 = data.groupby(\'校园卡号\').sum()[[\'消费金额\']]
data_2.columns = [\'总消费金额\']
data_3 = data.groupby(\'校园卡号\').count()[[\'消费时间\']]
data_3.columns = [\'总消费次数\']
data_123 = pd.concat([data_1, data_2, data_3], axis=1)#.reset_index(drop=True)
data_123.head()
# 构建聚类模型
from sklearn.cluster import KMeans
# k为聚类类别,iteration为聚类最大循环次数,data_zs为标准化后的数据
k = 3 # 分成几类可以在此处调整
iteration = 500
data_zs = 1.0 * (data_123 - data_123.mean()) / data_123.std()
# n_jobs为并发数
model = KMeans(n_clusters=k, n_jobs=4, max_iter=iteration, random_state=1234)
model.fit(data_zs)
# r1统计各个类别的数目,r2找出聚类中心
r1 = pd.Series(model.labels_).value_counts()
r2 = pd.DataFrame(model.cluster_centers_)
r = pd.concat([r2,r1], axis=1)
r.columns = list(data_123.columns) + [\'类别数目\']
# 选出消费总额最低的500名学生的消费信息
data_500 = data.groupby(\'校园卡号\').sum()[[\'消费金额\']]
data_500.sort_values(by=[\'消费金额\'],ascending=True,inplace=True,na_position=\'first\')
data_500 = data_500.head(500)
data_500_index = data_500.index.values
data_500 = data[data[\'校园卡号\'].isin(data_500_index)]
data_500.head(10)
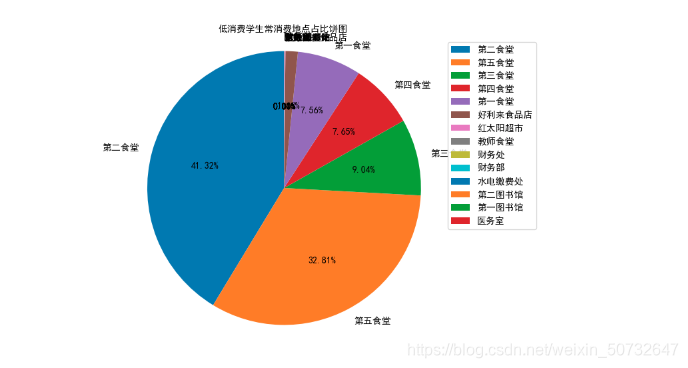
# 绘制饼图
canteen_name = list(data_max_place.index)
man_count = list(data_max_place.values)
# 创建画布
plt.figure(figsize=(10, 6), dpi=50)
# 绘制饼图
plt.pie(man_count, labels=canteen_name, autopct=\'%1.2f%%\', shadow=False, startangle=90, textprops={\'fontproperties\':font})
# 显示图例
plt.legend(prop=font)
# 添加标题
plt.title("低消费学生常消费地点占比饼图", fontproperties=font)
# 饼图保持圆形
plt.axis(\'equal\')
# 显示图像
plt.show()