大周末的,不犒劳一下自己,怎么对得起一周的辛勤工作呢,对吧。
那么跟我一起来爬一下你所在的城市美食吧
基本开发环境
-
Python 3.6
-
Pycharm
相关模块的使用
# 爬虫模块使用 import requests import re import csv # 数据分析模块 import pandas as pd import numpy as np from pyecharts.charts import * from pyecharts import options as opts from pyecharts.globals import ThemeType #引入主题
安装Python并添加到环境变量,pip安装需要的相关模块即可。
兄弟们学习python,有时候不知道怎么学,从哪里开始学。掌握了基本的一些语法或者做了两个案例后,不知道下一步怎么走,不知道如何去学习更加高深的知识。
那么对于这些大兄弟们,我准备了大量的免费视频教程,PDF电子书籍,以及视频源的源代码!
还会有大佬解答!
都在这个群里了 点击蓝色字体(我)获取
欢迎加入,一起讨论 一起学习!
那么对于这些大兄弟们,我准备了大量的免费视频教程,PDF电子书籍,以及视频源的源代码!
还会有大佬解答!
都在这个群里了 点击蓝色字体(我)获取
欢迎加入,一起讨论 一起学习!
需求数据来源分析
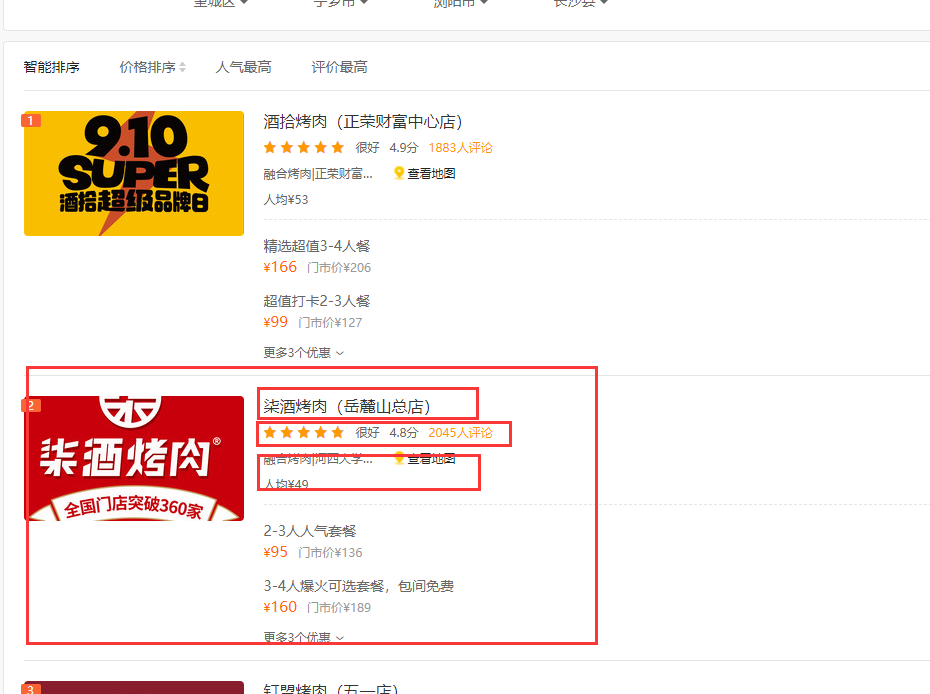

某团上面这些数据都是可以获取的,当然还有商家的电话也是可以的。
一般去找数据的话都是从开发者工具里面进行抓包分析,复制想要的数据内容然后进行搜索。
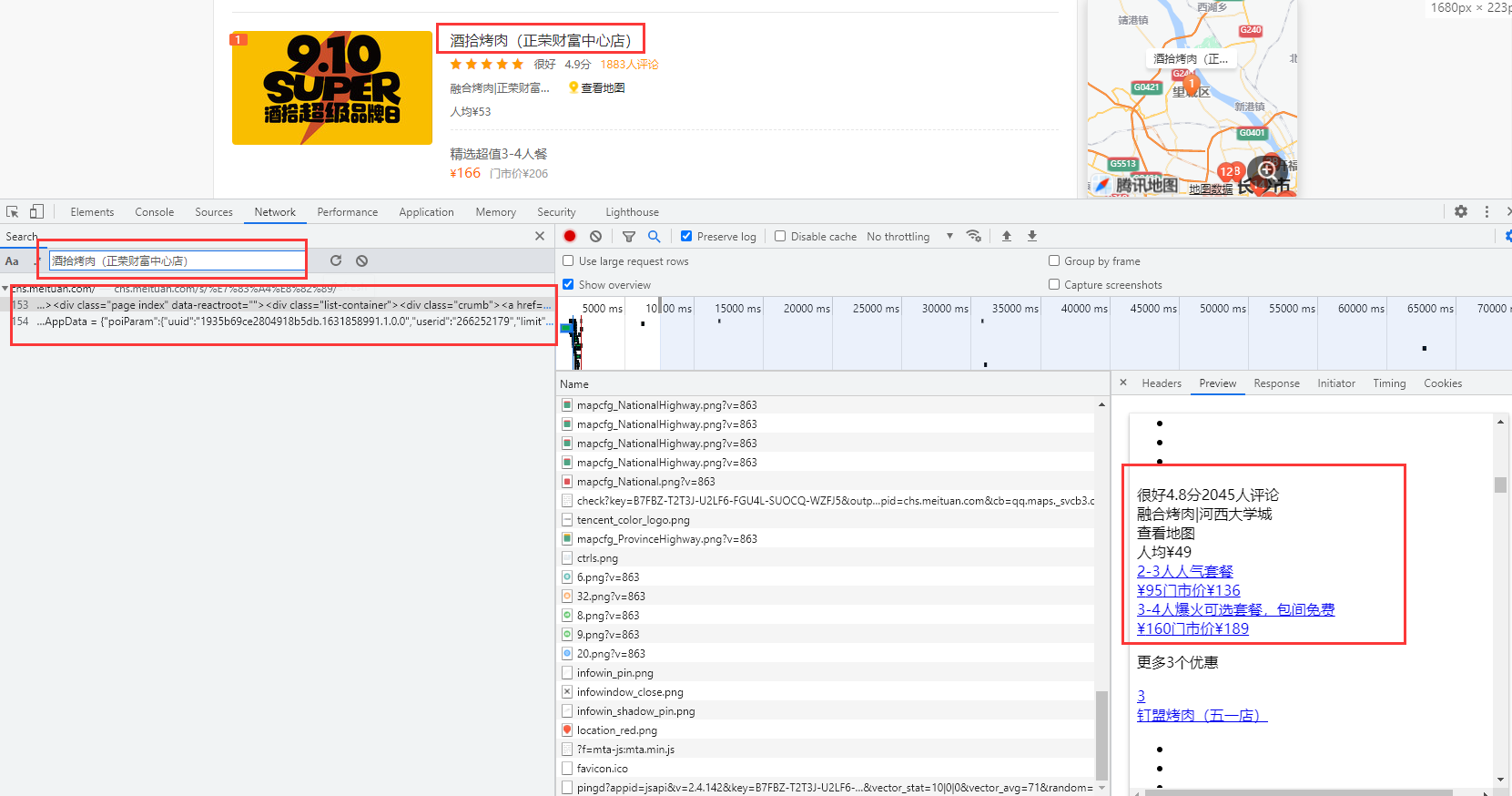
如果是这样找数据的话,是没有什么问题的,但是对于美团这个网站来说,这样没有办法进行多页数据爬取。
某团的数据要从第二页找,这样才能进行多页数据爬取。
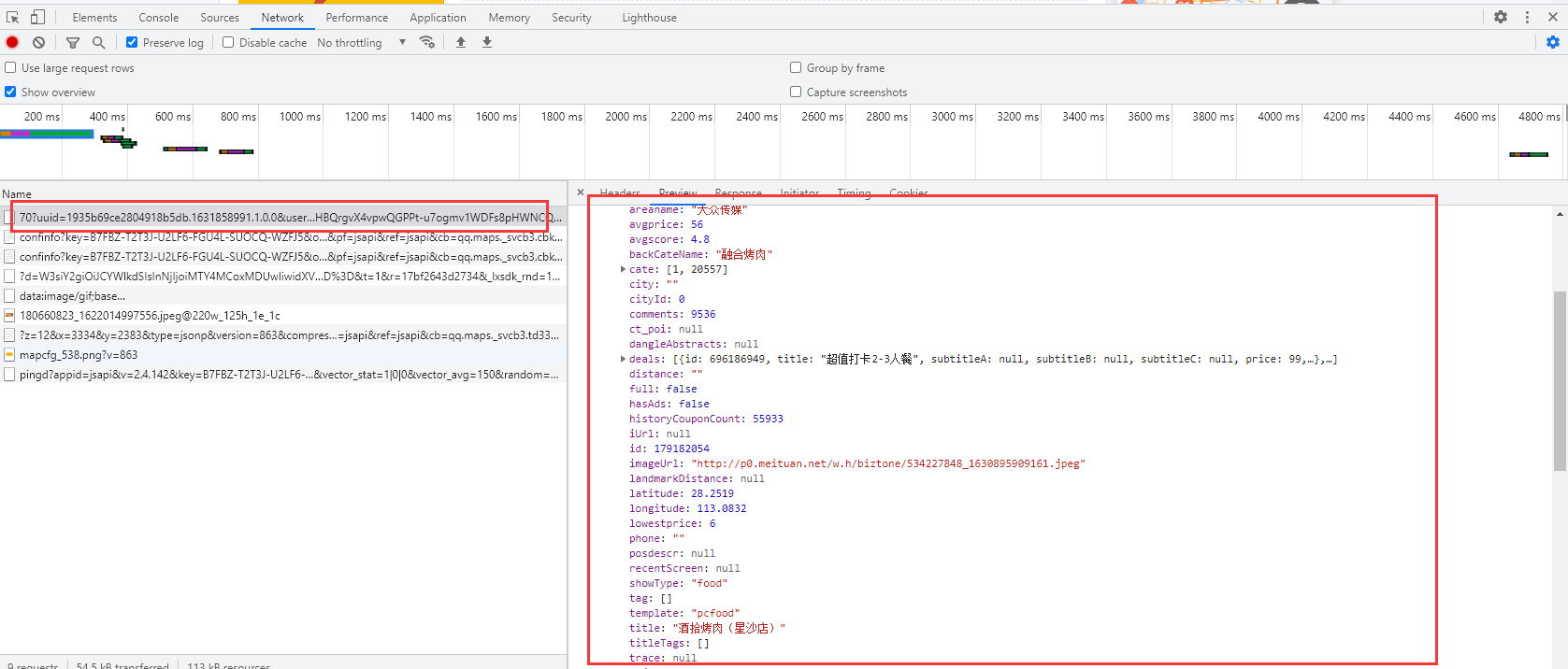
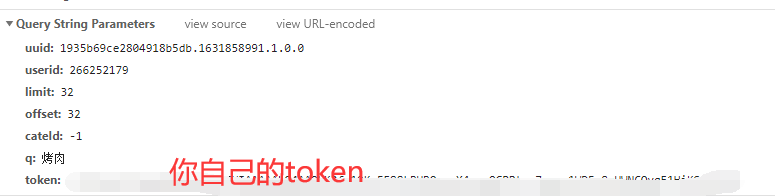
代码实现
for page in range(0, 1537, 32): # time.sleep(2) url = \'https://apimobile.meituan.com/group/v4/poi/pcsearch/30\' data = { \'uuid\': \'96d0bfc90dfc441b81fb.1630669508.1.0.0\', \'userid\': \'266252179\', \'limit\': \'32\', \'offset\': page, \'cateId\': \'-1\', \'q\': \'烤肉\', \'token\': \'你自己的token\', } headers = { \'Referer\': \'https://sz.meituan.com/\', \'User-Agent\': \'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36\' } response = requests.get(url=url, params=data, headers=headers) result = response.json()[\'data\'][\'searchResult\'] for index in result: shop_id = index[\'id\'] index_url = f\'https://www.meituan.com/meishi/{shop_id}/\' dit = { \'店铺名称\': index[\'title\'], \'人均消费\': index[\'avgprice\'], \'店铺评分\': index[\'avgscore\'], \'评论人数\': index[\'comments\'], \'所在商圈\': index[\'areaname\'], \'店铺类型\': index[\'backCateName\'], \'详情页\': index_url, } csv_writer.writerow(dit) print(dit) f = open(\'美团烤肉数据.csv\', mode=\'a\', encoding=\'utf-8\', newline=\'\') csv_writer = csv.DictWriter(f, fieldnames=[ \'店铺名称\', \'人均消费\', \'店铺评分\', \'评论人数\', \'所在商圈\', \'店铺类型\', \'详情页\', ]) csv_writer.writeheader()
爬取数据展示
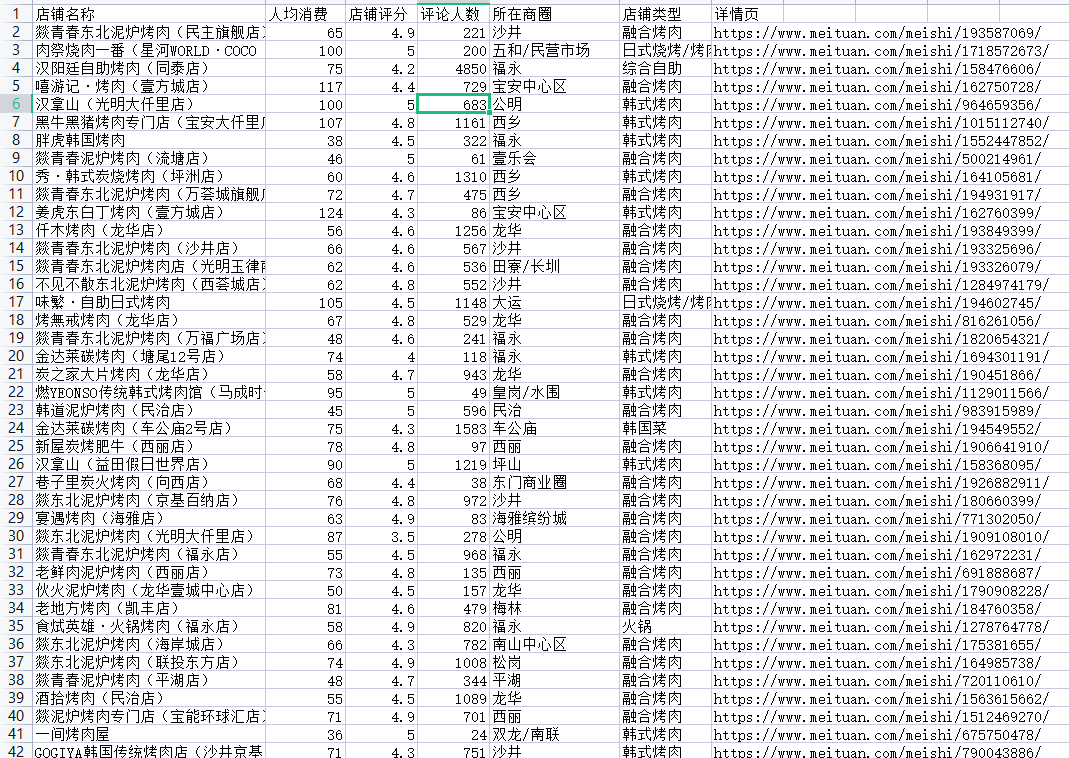
数据分析代码实现及效果
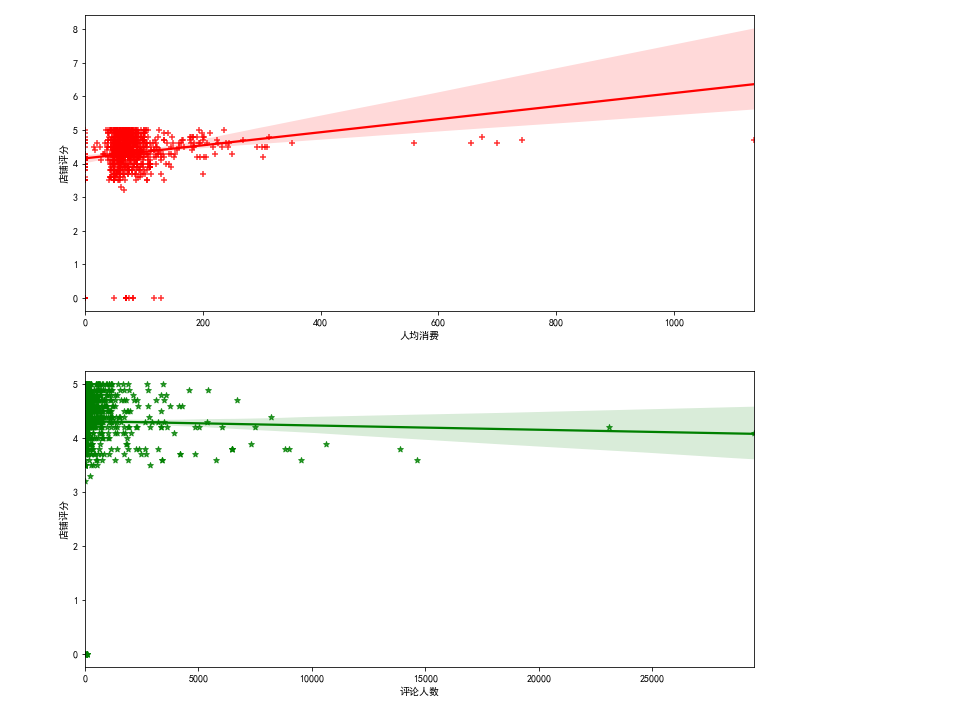
import matplotlib.pyplot as plt import seaborn as sns %matplotlib inline plt.rcParams[\'font.sans-serif\'] = [\'SimHei\'] # 设置加载的字体名 plt.rcParams[\'axes.unicode_minus\'] = False # 解决保存图像是负号\'-\'显示为方块的问题 fig,axes=plt.subplots(2,1,figsize=(12,12)) sns.regplot(x=\'人均消费\',y=\'店铺评分\',data=df,color=\'r\',marker=\'+\',ax=axes[0]) sns.regplot(x=\'评论人数\',y=\'店铺评分\',data=df,color=\'g\',marker=\'*\',ax=axes[1])
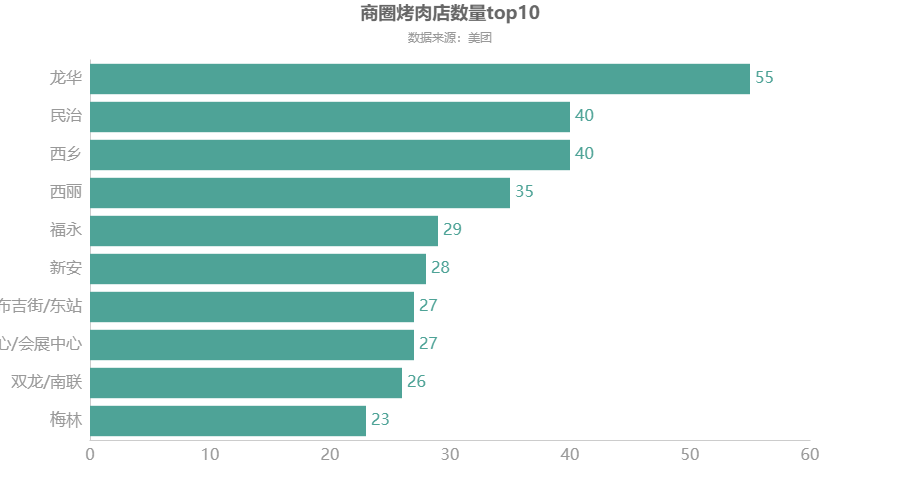
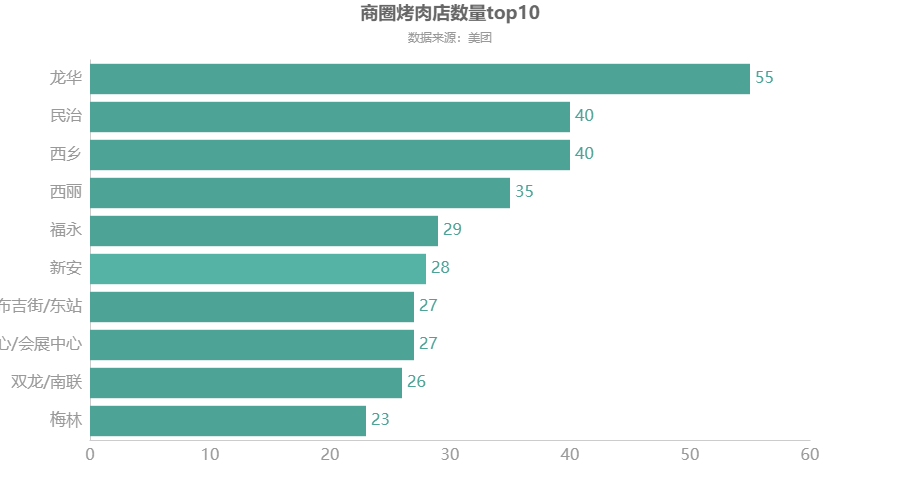
所在商圈烤肉店铺数量top10
df2 = df.groupby(\'所在商圈\')[\'店铺名称\'].count() df2 = df2.sort_values(ascending=True)[-10:] df2 = df2.round(2) c = ( Bar(init_opts=opts.InitOpts(theme=ThemeType.WONDERLAND)) .add_xaxis(df2.index.to_list()) .add_yaxis("",df2.to_list()).reversal_axis() #X轴与y轴调换顺序 .set_global_opts(title_opts=opts.TitleOpts(title="商圈烤肉店数量top10",subtitle="数据来源:美团",pos_left = \'center\'), xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(font_size=16)), #更改横坐标字体大小 yaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(font_size=16)), #更改纵坐标字体大小 ) .set_series_opts(label_opts=opts.LabelOpts(font_size=16,position=\'right\')) ) c.render_notebook()
商圈烤肉店铺评分top10
df4 = df.groupby(\'评分类型\')[\'店铺名称\'].count() df4 = df4.sort_values(ascending=False) regions = df4.index.to_list() values = df4.to_list() c = ( Pie(init_opts=opts.InitOpts(theme=ThemeType.WONDERLAND)) .add("", zip(regions,values)) .set_global_opts(title_opts=opts.TitleOpts(title="不同评分类型店铺数量",subtitle="数据来源:美团",pos_top="-1%",pos_left = \'center\')) .set_series_opts(label_opts=opts.LabelOpts(formatter="{b}:{d}%",font_size=18)) ) c.render_notebook()
不同评分类型店铺数量
df4 = df.groupby(\'评分类型\')[\'店铺名称\'].count() df4 = df4.sort_values(ascending=False) regions = df4.index.to_list() values = df4.to_list() c = ( Pie(init_opts=opts.InitOpts(theme=ThemeType.WONDERLAND)) .add("", zip(regions,values)) .set_global_opts(title_opts=opts.TitleOpts(title="不同评分类型店铺数量",subtitle="数据来源:美团",pos_top="-1%",pos_left = \'center\')) .set_series_opts(label_opts=opts.LabelOpts(formatter="{b}:{d}%",font_size=18)) ) c.render_notebook()
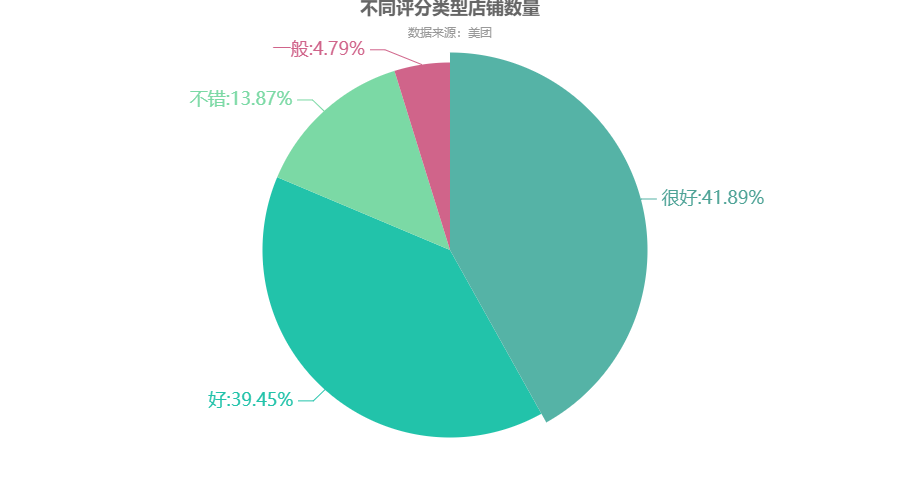
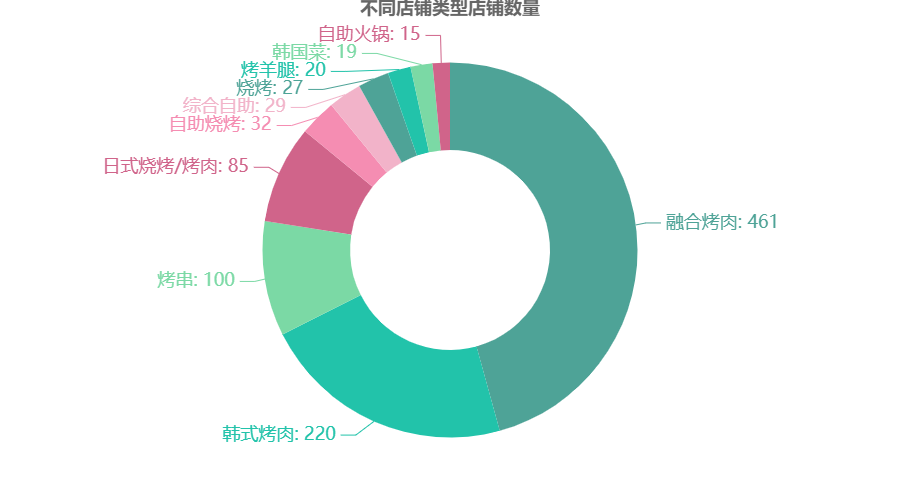
不同店铺类型店铺数量
df6 = df.groupby(\'店铺类型\')[\'店铺名称\'].count() df6 = df6.sort_values(ascending=False)[:10] df6 = df6.round(2) regions = df6.index.to_list() values = df6.to_list() c = ( Pie(init_opts=opts.InitOpts(theme=ThemeType.WONDERLAND)) .add("", zip(regions,values),radius=["40%", "75%"]) .set_global_opts(title_opts=opts.TitleOpts(title="不同店铺类型店铺数量",pos_top="-1%",pos_left = \'center\')) .set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}",font_size=18)) ) c.render_notebook()
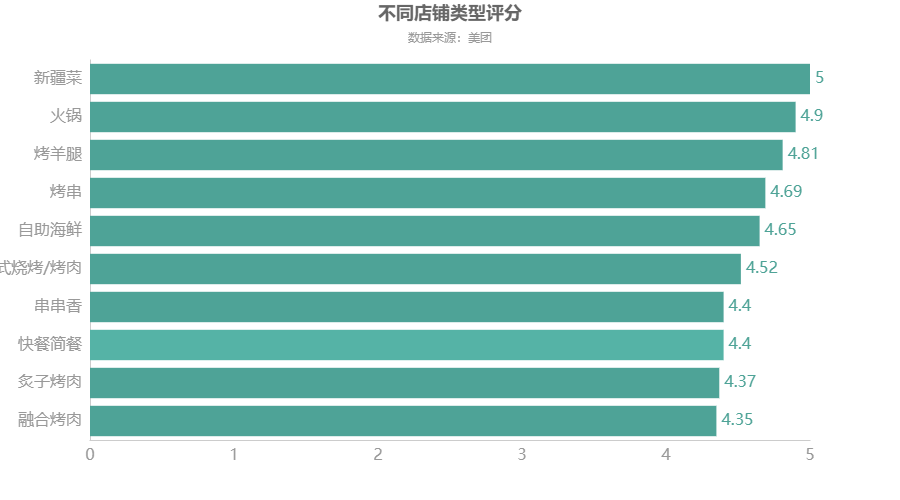
不同店铺类型店铺评分
df6 = df.groupby(\'店铺类型\')[\'店铺评分\'].mean() df6 = df6.sort_values(ascending=True) df6 = df6.round(2) df6 = df6.tail(10) c = ( Bar(init_opts=opts.InitOpts(theme=ThemeType.WONDERLAND)) .add_xaxis(df6.index.to_list()) .add_yaxis("",df6.to_list()).reversal_axis() #X轴与y轴调换顺序 .set_global_opts(title_opts=opts.TitleOpts(title="不同店铺类型评分",subtitle="数据来源:美团",pos_left = \'center\'), xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(font_size=16)), #更改横坐标字体大小 yaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(font_size=16)), #更改纵坐标字体大小 ) .set_series_opts(label_opts=opts.LabelOpts(font_size=16,position=\'right\')) ) c.render_notebook()
不同店铺类型店铺评论人数
df7 = df.groupby(\'店铺类型\')[\'评论人数\'].sum() df7 = df7.sort_values(ascending=True) df7 = df7.tail(10) c = ( Bar(init_opts=opts.InitOpts(theme=ThemeType.WONDERLAND)) .add_xaxis(df7.index.to_list()) .add_yaxis("",df7.to_list()).reversal_axis() #X轴与y轴调换顺序 .set_global_opts(title_opts=opts.TitleOpts(title="不同店铺类型评论人数",subtitle="数据来源:美团",pos_left = \'center\'), xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(font_size=16)), #更改横坐标字体大小 yaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(font_size=16)), #更改纵坐标字体大小 ) .set_series_opts(label_opts=opts.LabelOpts(font_size=16,position=\'right\')) ) c.render_notebook()
把地方改成你们相对应的地点,找到自己喜欢吃的地方,快带约上自己的女朋友、小伙伴一起去打卡吧~
如果觉得有帮助,记得点赞收藏转发哈~
小编的动力来自于你们的喜欢
