系列文章
0. 序言
本文将继续用扑克牌作为示例,学习一些操作数据的方法,主要包括对数据进行「增、删、改、查」。
首先,我们创建一个空白的数据框。
import numpy as np
import pandas as pd
# 创建一个空白数据框
df = pd.DataFrame()
1. 如何增加数据?
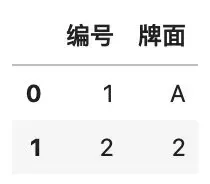
当我们给数据框中不存在的列赋值时,会自动增加一个新的列,比如说,要在空白数据框中增加一列「编号」,其中包含两行数字,使用下面的代码即可实现。
# 增加两行一列
df[\'编号\'] = [1, 2]
df
如果要在指定的位置插入列,那么可以使用 insert() 函数,例如:
# 增加一列
df.insert(1, \'牌面\', [\'A\', 2])
df
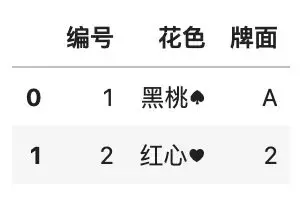
用类似的方法,可以把新增的列插到中间的位置。
# 中间再增加一列
df.insert(1, \'花色\', [\'黑桃♠\', \'红心♥\'])
df
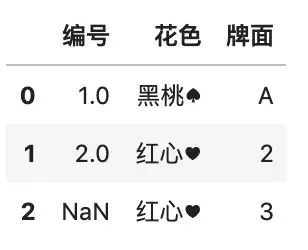
为了演示增加行的方法,我们首先创建一个新的数据框,其中包含一张扑克牌,我们使用 append() 函数把这张新牌增加到数据框中去。
# 定义一张新牌
poker1 = pd.DataFrame(
{\'花色\': [\'红心♥\'],
\'牌面\': [3]}
)
# 增加一行
df2 = df.append(
poker1,
ignore_index=True,
sort=False
)
df2
除了 append() 函数以外,还可以使用 concat() 函数来实现,下面代码返回的结果和上面一样。
# 默认按行的方向拼接两个数据框
pd.concat([df, poker1],
ignore_index=True,
sort=False)
如果要按列的方向拼接两个数据框,那么可以在 concat() 的参数中指定 axis=1,也可以使用 merge() 和 join() 函数代替,关于后面这两个函数的使用方法,我计划放在《如何用 Python 整理数据》中进行介绍,敬请关注林骥公众号的后续更新。
2. 如何删除数据?
使用 drop() 函数,可以按索引删除对应的行或列,默认是删除行,并生成一个新的数据框。
# 删除索引为 0 和 2 的行
df2.drop([0, 2])

如果想要删除列,那么需要指定 axis=1。
# 删除「花色」列
df2.drop([\'花色\'], axis=1)
与 drop() 函数不同的是,del 语句会直接删除原来数据框中的列,所以使用 del 时需要更加谨慎。
# 删除「编号」列,用 del 会改变原来的数据
del df2[\'编号\']
df2
3. 如何修改数据?
使用 replace() 函数,可以替换所有匹配的数据。
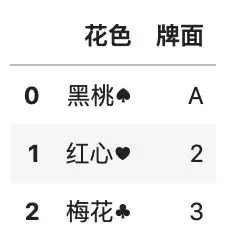
# 将所有的 A 修改为 1
df3 = df2.replace(\'A\', 1)
df3
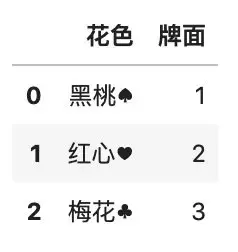
通过传递 regex 参数,可以使用正则表达式,实现模糊替换,例如:
# 将所有的符号剔除
df3.replace(
[\'♠\', \'♥\', \'♣\', \'♦\'], \'\',
regex=True
)
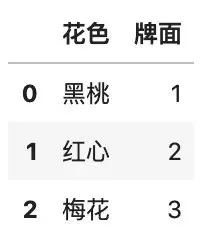
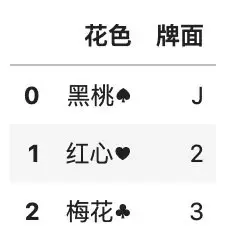
如果想要修改某行某列指定的值,那么用 loc 定位之后,直接赋值即可。
# 修改某一个值
df3.loc[0, \'牌面\'] = \'J\'
df3
如果想要修改所有的列名,那么可以用一个列表来进行赋值。
# 修改列名
df3.columns = list(\'AB\')
df3
如果只是想修改某一列或几列的列名,那么可以使用 rename() 函数指定 axis=1 来实现。
# 修改指定列名
df3.rename(
{\'A\': \'花色\'},
axis=1
)
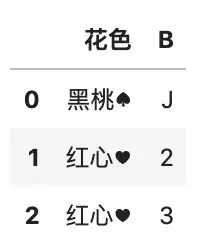
如果 rename() 函数不指定 axis 参数,那么默认修改的是行索引。
# 修改指定行索引
df3.rename({1:3, 2:3})
4. 如何查询数据?
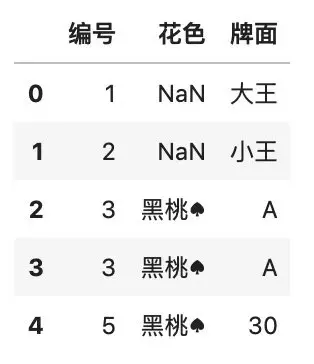
我们先从 Excel 文件中读取想要查询的数据,并用 head() 函数查询前 5 行数据。
# 从 Excel 文件中读取原始数据
df = pd.read_excel(
\'待清洗的扑克牌数据集.xlsx\'
)
# 查询前 5 行的数据
df.head()
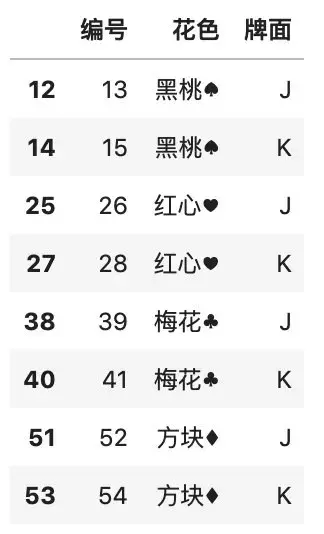
下面我们导入处理正则表达式的 re 模块,然后使用 match() 函数实现模糊查询,其中 flags=re.IGNORECASE 表示不区分大小写。
# 用正则表达式匹配「牌面」包含 j 或 k 的牌
import re
df[df.牌面.str.match(
\'[jk]\', flags=re.IGNORECASE, na=False
)]
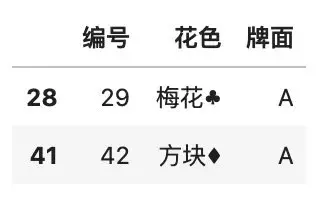
query() 是一个非常实用而且高效的查询函数。
# 查询索引在 1 到 5 之间,且牌面不是 A 和 30
card = [\'A\', \'30\']
df.query(
\'1 <= index <= 5 \
and 牌面 not in @card \'
)
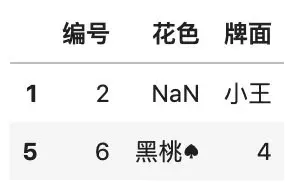
使用 query(),还可以直接在表达式中使用统计函数,例如:
# 查询编号大于平均值,且牌面为 A
card = [\'A\', \'30\']
df.query(
\'编号 > 编号.mean() \
and 牌面 == "A" \'
)
个人强烈推荐使用 query() 查询数据,它的语法与 SQL 类似,功能非常强大。
5. 应用案例
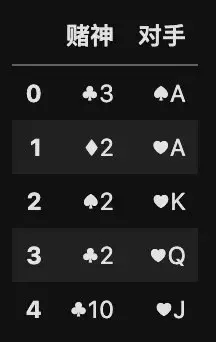
我们还原电影《赌神 3 之少年赌神》的一个场景,其中的扑克牌玩法是梭哈,每人 5 张牌,牌型的大小顺序是:同花顺 > 四条 > 葫芦(三条加对子) > 同花 > 顺子 >三条 > 二对 > 对子 > 散牌。

电影中赌到最后一把牌的时候,赌神和对手的牌分别是这样的:
# 赌神的牌
x = pd.DataFrame({
\'赌神\':[\'♣3\',\'♦2\',\'♠2\',\'♣2\',\'♣10\']
})
# 对手的牌
y = pd.DataFrame({
\'对手\':[\'♠A\',\'♥A\',\'♥K\',\'♥Q\',\'♥J\']
})
# 把赌神和对手的牌合并在一起显示
pd.concat([x, y], axis=1)
为了报仇,赌神高进将计就计,用戒指暗藏了红心♥️ 10 的牌角,让对手高傲以为交换底牌之后就能赢。但其实底牌是一张梅花♣️ 3,所以交换底牌之后,仍然是赌神赢。
在 Python 中,交换变量有一种非常简便的办法:
# 交换赌神和对手的底牌
x.loc[0][0], y.loc[0][0] = y.loc[0][0], x.loc[0][0]
pd.concat([x, y], axis=1)
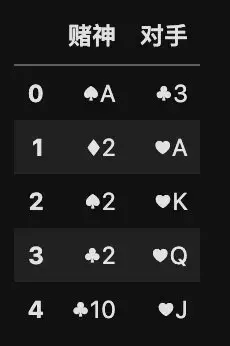
这种方法不需要借助临时变量,直接用 a,b = b,a 的形式实现变量交换,非常方便实用。
6. 小结
最后,用一张思维导图,作为本文的小结。