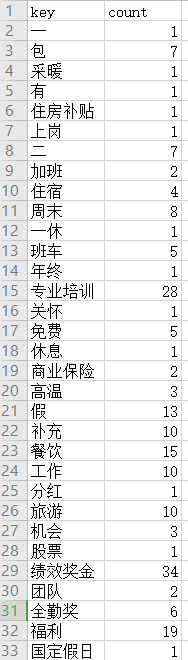
为了结果直观,做的简单
网页地址:
https://search.51job.com/list/180200,000000,0000,00,9,99,%25E6%25AD%25A6%25E6%25B1%2589,2,1.html?lang=c&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare=
# -*- coding:utf-8 -*-
import requests
from lxml import etree
from wordcloud import WordCloud
# 写入csv
def write_csv(name, row):
reload(sys)
sys.setdefaultencoding("utf-8")
# 统计出现频率
def get_count(text):
wordlist_jieba = jieba.cut(text)
# jieba分词
def chinese_jieba(text):
wordlist_jieba = jieba.cut(text)
text_jieba = " ".join(wordlist_jieba)
return text_jieba
# 生成词云图
def get_ciyun(text):
text = chinese_jieba(text)
print(text)
# mask_pic = numpy.array(Image.open(os.path.join(cur_path, "bit.jpg")))
# print(text)
# 背景颜色 词数量 词字体大小 字体文件路径(需要放到和py文件同一个路径下) 去掉的词 遮罩层
font_path = path.join(d, \'fonts\', \'Symbola\', \'Symbola.ttf\')
image.show()
#获取数据
def get_data(url):
result = \'\'
headers={\'Host\':\'search.51job.com\',\'Upgrade-Insecure-Requests\':\'1\',\'User-Agent\':\'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko)\ Chrome/63.0.3239.132 Safari/537.36\'}
return result
# 主程序
def main():
url = \'https://search.51job.com/list/180200,000000,0000,00,9,99,%25E6%25AD%25A6%25E6%25B1%2589,2,1.html?lang=c&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&ord_field=0&dibiaoid=0&line=&welfare=\'
text = get_data(url)
#print("获取完毕,分词生成词云")
get_ciyun(text)
get_count(text)
main()
网页:

结果
1 抓取结果

2 词云图

3 统计词频