使用梯度下降算法进行学习
现在我们有了一个神经网络,接下来我们需要的就是一个训练数据集。该书采用的是 MNIST 数据集。
我们希望能够找到合适的一组权重及偏置,使得数据能够全部被正确地分类。为了量化我们与这个目标的距离,我们定义一个代价函数(也被称为损失函数或目标函数): 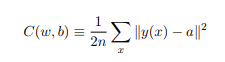 其中w是神经网络中权重的集合,b为所有的偏置,n为输入数据的个数,y(x)为理想的结果,a为当前神经网络的输出值。实际上,a取决于x、w和b,但为了保持函数的简洁,这里使用a代替。
我们称C为二次代价函数,或均方误差(Mean Squared Error,MSE)。它有两个特征:一、C总为非负值,因为其中的每一项都是非负的。二、我们的计算结果越接近真实结果,C的值就越小。因此,我们的目标就转化为,想办法把C的值降为最小。为了实现这个目标,我们引入了梯度下降算法。
这里有一个疑问,那就是为何要专门设计一个函数来表示分类结果的精度,而不是简单地使用分类正确的图片数作为评价标准呢?
这是因为后者不是一个关于权重和偏置敏感及平滑的函数,往往我们对权重或偏置做出改变时,分类正确的图片数却并没有发生任何改变。这会使我们很难理解这次改变对神经网络性能的影响。因此,我们选取了一个能够对权重和偏置的改变更敏感的二次函数来表示分类精度。
接下来假设C是一个二元函数,其具有以下的图像:
对于这个函数,我们一眼就能看出其最小值,但对于大多数函数,我们并不能这样做,尤其是对那些变量超过两个的函数。也许求导是一个好的方法,但在神经网络中往往会使用大量的变量,这使得求导变成了噩梦。
幸运的是,梯度下降方法可以解决这个问题。为了理解该算法的原理,我们不妨把函数想象成一个山谷(如上图),现在有一个小球从山谷的斜坡滚落下来。我们知道这个小球最终会落到山谷的最低点,那么如果我们计算小球的运动,并最终计算它的停止点,不久可以算出"山谷"的最低点,也就是函数的最小值吗?
为了简化问题,在这里我们并不考虑任何物理定律,仅仅假设小球会向比它当前所处位置更低的方向运动。
当我们让小球沿v1和v2移动一个微小的距离时,C的变化如下:
我们的目的是找到最小的C,所以我们选择的v1和v2的移动方向应该是是C变小的方向,直到它不会变小为止。
为此我们定义Δv为表示v变化的向量,即
同时我们定义C的梯度为C关于v1和v2的偏导组成的向量,我们用来表示。即:
于是上式可以写为:
于是我们知道该如何选取Δv了,我们令:
这里η 是一个很小的正数(我们称为学习效率)。由上述方程我们可以得到:
由于
于是ΔC≤0。也就是说,如果我们在上述函数的约束条件下去改变v的值,C的值就会一直减小,这正和我们的目的相合。
事实上,甚⾄有⼀种观点认为梯度下降法是求最⼩值的最优策略。假设我们努⼒去改变
∆v 来让 C 尽可能地减⼩。这相当于最⼩化 ∆C ≈ ∇C · ∆v。我们⾸先限制步⻓为非常小的固定值,
即 ∥∆v∥ = ϵ,ϵ > 0。当步⻓固定时,我们要找到使得 C 减⼩最⼤的下降⽅向。可以证明,使得
∇C · ∆v 取得最⼩值的 ∆v 为 ∆v = −η∇C,这⾥ η = ϵ/∥∇C∥ 是由步⻓的限制 ∥∆v∥ = ϵ 所决定
的。因此,梯度下降法可以被视为⼀种在 C 下降最快的⽅向上做微⼩变化的⽅法。
课后习题:
1:
Prove the assertion of the last paragraph. Hint: If you’re not already familiar with the Cauchy-Schwarz inequality, you may find it helpful to familiarize yourself with it.
2:
I explained gradient descent when C is a function of two variables, and when it’s a function of more than two variables. What happens when C is a function of just one variable? Can you provide a geometric interpretation of what gradient descent is doing in the one-dimensional case?
待解…